GPU-Rich Labs Have Won: What's Left for the Rest of Us is Distillation
Michael Ryaboy
•Published on Jul 31, 2025

Word on the street is that OpenAI now spends $50M+ just on LLM training a day. Working to compete on superintelligence without country-scale resources is pretty much futile. Despite this, massive training runs and powerful but expensive models means another technique is starting to dominate: distillation.
2024 was the year of wasteful AI enterprise spending. Fortune-500 companies would spend tens of millions and proudly announce that they trained their own SOTA models, only to have them be antiquated months or weeks after their release. Large labs like OpenAI and Anthropic would immediately release a new model that would perform better at the specific tasks these companies cared about than the very models they spent so much money and time training!
Impressively, open source models have been able to quickly catch up to big labs. This is partly because of creativity under constraint, but the dominant strategy is the quiet distillation of large proprietary models. Deepseek is the most impressive example of both of these.
Open-source has been lagging behind proprietary models for years, but lately this gap has been widening. Here's a look at LMArena, for example:
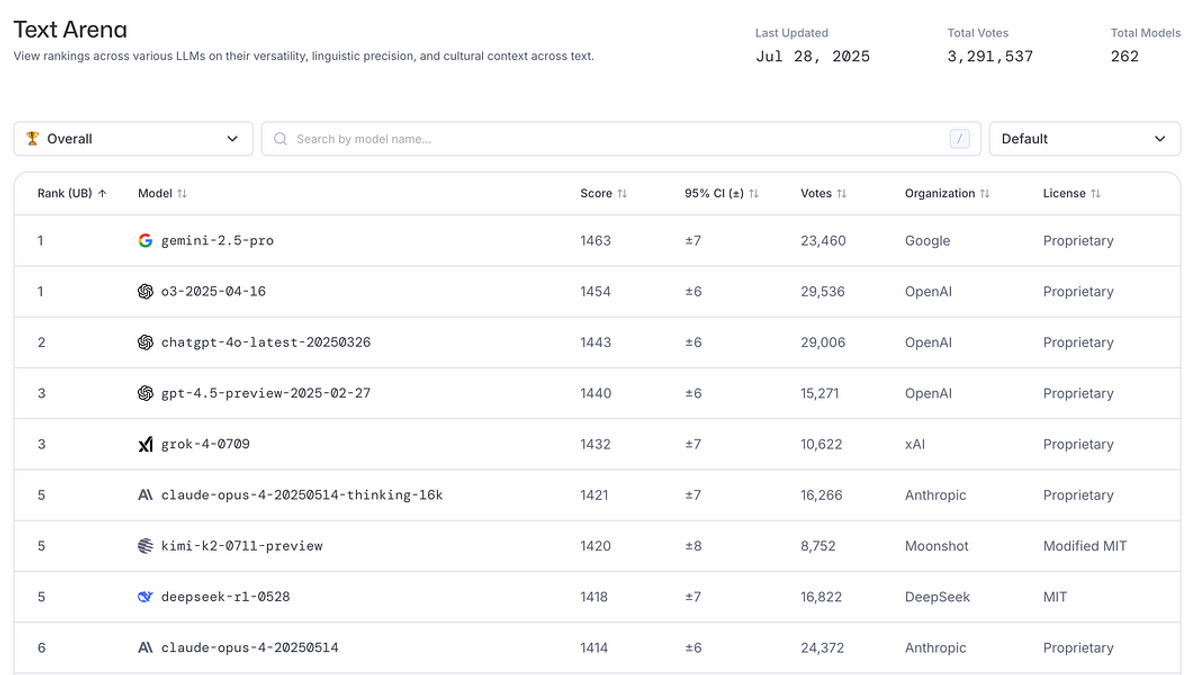
Even with the "generosity" of Meta and Alibaba (Qwen), who have spent hundreds of millions just to release model weights, open source simply cannot compete with the hegemony of superintelligence labs when it comes to general intelligence. The gap in GPU wealth is difficult to fully grok. The largest labs either own or have access to 200k+ H100/H200 equivalent GPUs. The first model that takes $1B to train will not be released for free.
2025 is the year of agents and the application layer. Through many expensive lessons, enterprises realized that training large models is a waste of time. Instead, easy wins come from building on the smallest LLM available that can solve a particular task acceptably. Most companies found that by not worrying about training, they can still serve their users and eke out margins. If an LLM can't solve a particular task acceptably yet, it's not the worst strategy to build what's possible now and wait a couple of months.
Still, LLMs prove to cut into margins more than most software, and the large models that seem to be able to solve any task also come with significant latency.
Most applications don't need superintelligence, instead they need low-latency models that are good enough for a task. Whether that task is data extraction, classification, or research, they need something cheap and fast enough to deploy to millions of users and maximize margins.
Luckily, when you have superintelligent models who can perform any task well, training a smaller model is extremely easy through a process called distillation. Distillation takes the outputs of a large model and trains a smaller pre-trained model on it in a process called Supervised Fine Tuning (SFT), typically conserving 95%+ of the performance while being an order of magnitude faster/cheaper.
Distillation is the second step after product market fit. Once you have users and significant costs, distillation can expand margins and reduce latency without impacting quality.
The challenge with distillation is that you need experience to distill and evaluate models effectively. And once you train, it's not trivial to deploy models.
That's what we are solving at Inference.net. End-to-end distillation and inference for busy founders that just want to focus on the application layer. If you have 30k+/mo in model spend, we'd love to chat.