'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6665%2025.6402L24.8887%2027.8624L29.8887%2022.8624M20.8151%2016.5498C21.7082%2016.4786%2022.5561%2016.1273%2023.2381%2015.5462C24.8295%2014.19%2027.1701%2014.19%2028.7615%2015.5462C29.4434%2016.1273%2030.2913%2016.4786%2031.1845%2016.5498C33.2687%2016.7162%2034.9238%2018.3712%2035.0901%2020.4555C35.1614%2021.3486%2035.5126%2022.1965%2036.0938%2022.8785C37.4499%2024.4699%2037.4499%2026.8105%2036.0938%2028.4019C35.5126%2029.0838%2035.1614%2029.9317%2035.0901%2030.8249C34.9238%2032.9091%2033.2687%2034.5642%2031.1845%2034.7305C30.2913%2034.8018%2029.4434%2035.153%2028.7615%2035.7341C27.1701%2037.0903%2024.8295%2037.0903%2023.2381%2035.7341C22.5561%2035.153%2021.7082%2034.8018%2020.8151%2034.7305C18.7308%2034.5642%2017.0758%2032.9091%2016.9094%2030.8249C16.8382%2029.9317%2016.487%2029.0838%2015.9058%2028.4019C14.5496%2026.8105%2014.5496%2024.4699%2015.9058%2022.8785C16.487%2022.1965%2016.8382%2021.3486%2016.9094%2020.4555C17.0758%2018.3712%2018.7308%2016.7161%2020.8151%2016.5498Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_411_10857'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_411_10857'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_411_10857'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_411_10857'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M21.5556%2015.6401H19.5556C18.311%2015.6401%2017.6887%2015.6401%2017.2134%2015.8823C16.7952%2016.0954%2016.4553%2016.4354%2016.2422%2016.8535C16%2017.3289%2016%2017.9511%2016%2019.1957V21.1957M21.5556%2035.6401H19.5556C18.311%2035.6401%2017.6887%2035.6401%2017.2134%2035.3979C16.7952%2035.1849%2016.4553%2034.8449%2016.2422%2034.4268C16%2033.9514%2016%2033.3291%2016%2032.0846V30.0846M36%2021.1957V19.1957C36%2017.9511%2036%2017.3289%2035.7578%2016.8535C35.5447%2016.4354%2035.2048%2016.0954%2034.7866%2015.8823C34.3113%2015.6401%2033.689%2015.6401%2032.4444%2015.6401H30.4444M36%2030.0846V32.0846C36%2033.3291%2036%2033.9514%2035.7578%2034.4268C35.5447%2034.8449%2035.2048%2035.1849%2034.7866%2035.3979C34.3113%2035.6401%2033.689%2035.6401%2032.4444%2035.6401H30.4444M30.4444%2025.6401C30.4444%2028.0947%2028.4546%2030.0846%2026%2030.0846C23.5454%2030.0846%2021.5556%2028.0947%2021.5556%2025.6401C21.5556%2023.1855%2023.5454%2021.1957%2026%2021.1957C28.4546%2021.1957%2030.4444%2023.1855%2030.4444%2025.6401Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_2040'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_2040'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_2040'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M23.7778%2031.9275V34.5291C23.7778%2035.7564%2024.7727%2036.7513%2026%2036.7513C27.2273%2036.7513%2028.2222%2035.7564%2028.2222%2034.5291V31.9275M26%2014.5291V15.6402M16%2025.6402H14.8889M18.7778%2018.4179L18.111%2017.7512M33.2222%2018.4179L33.8892%2017.7512M37.1111%2025.6402H36M32.6667%2025.6402C32.6667%2029.3221%2029.6819%2032.3068%2026%2032.3068C22.3181%2032.3068%2019.3333%2029.3221%2019.3333%2025.6402C19.3333%2021.9583%2022.3181%2018.9735%2026%2018.9735C29.6819%2018.9735%2032.6667%2021.9583%2032.6667%2025.6402Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_17437'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_17437'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_17437'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2.33301'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.95801'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M18.5557%2022.6665H34.1112M18.5557%2029.3332H34.1112'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59239'%20x='0.833008'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59239'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59239'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='2.14014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.76514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M22.6667%2015.0288V17.251M29.3333%2015.0288V17.251M22.6667%2035.0288V37.251M29.3333%2035.0288V37.251M34.8889%2022.8066H37.1111M34.8889%2028.3621H37.1111M14.8889%2022.8066H17.1111M14.8889%2028.3621H17.1111M22.4444%2035.0288H29.5556C31.4224%2035.0288%2032.3558%2035.0288%2033.0689%2034.6655C33.6961%2034.3459%2034.206%2033.836%2034.5256%2033.2088C34.8889%2032.4957%2034.8889%2031.5623%2034.8889%2029.6955V22.5844C34.8889%2020.7175%2034.8889%2019.7841%2034.5256%2019.0711C34.206%2018.4439%2033.6961%2017.9339%2033.0689%2017.6143C32.3558%2017.251%2031.4224%2017.251%2029.5556%2017.251H22.4444C20.5776%2017.251%2019.6442%2017.251%2018.9311%2017.6143C18.3039%2017.9339%2017.794%2018.4439%2017.4744%2019.0711C17.1111%2019.7841%2017.1111%2020.7175%2017.1111%2022.5844V29.6955C17.1111%2031.5623%2017.1111%2032.4957%2017.4744%2033.2088C17.794%2033.836%2018.3039%2034.3459%2018.9311%2034.6655C19.6442%2035.0288%2020.5776%2035.0288%2022.4444%2035.0288ZM24.4444%2029.4733H27.5556C28.1778%2029.4733%2028.489%2029.4733%2028.7267%2029.3522C28.9357%2029.2456%2029.1057%2029.0756%2029.2122%2028.8666C29.3333%2028.6289%2029.3333%2028.3178%2029.3333%2027.6955V24.5844C29.3333%2023.9621%2029.3333%2023.6509%2029.2122%2023.4133C29.1057%2023.2042%2028.9357%2023.0342%2028.7267%2022.9277C28.489%2022.8066%2028.1778%2022.8066%2027.5556%2022.8066H24.4444C23.8222%2022.8066%2023.511%2022.8066%2023.2733%2022.9277C23.0643%2023.0342%2022.8943%2023.2042%2022.7878%2023.4133C22.6667%2023.6509%2022.6667%2023.9621%2022.6667%2024.5844V27.6955C22.6667%2028.3178%2022.6667%2028.6289%2022.7878%2028.8666C22.8943%2029.0756%2023.0643%2029.2456%2023.2733%2029.3522C23.511%2029.4733%2023.8222%2029.4733%2024.4444%2029.4733Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1117_10655'%20x='0.5'%20y='0.640137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1117_10655'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1117_10655'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)

'%3e%3crect%20x='1.66699'%20y='2'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.29199'%20y='2.625'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M35.667%2032.6667L34.5557%2033.8823C33.9664%2034.5269%2033.1672%2034.8889%2032.3338%2034.8889C31.5004%2034.8889%2030.7012%2034.5269%2030.1119%2033.8823C29.5217%2033.2391%2028.7225%2032.8779%2027.8894%2032.8779C27.0563%2032.8779%2026.2571%2033.2391%2025.667%2033.8823M15.667%2034.8889H17.5276C18.0711%2034.8889%2018.3429%2034.8889%2018.5986%2034.8275C18.8254%2034.7731%2019.0422%2034.6833%2019.241%2034.5615C19.4652%2034.424%2019.6574%2034.2319%2020.0418%2033.8475L34.0004%2019.8889C34.9208%2018.9684%2034.9208%2017.4761%2034.0004%2016.5556C33.0799%2015.6351%2031.5875%2015.6351%2030.667%2016.5556L16.7084%2030.5142C16.3241%2030.8985%2016.1319%2031.0907%2015.9945%2031.315C15.8726%2031.5138%2015.7828%2031.7306%2015.7284%2031.9573C15.667%2032.213%2015.667%2032.4848%2015.667%2033.0284V34.8889Z'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1851_59244'%20x='0.166992'%20y='0.5'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1851_59244'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1851_59244'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
'%3e%3crect%20x='2'%20y='1.64014'%20width='48'%20height='48'%20rx='24'%20fill='%23292929'/%3e%3crect%20x='2.625'%20y='2.26514'%20width='46.75'%20height='46.75'%20rx='23.375'%20stroke='%23636363'%20stroke-width='1.25'/%3e%3cpath%20d='M25.9998%2035.6401L25.8886%2035.4734C25.1168%2034.3156%2024.7309%2033.7368%2024.221%2033.3177C23.7696%2032.9467%2023.2495%2032.6684%2022.6905%2032.4986C22.059%2032.3068%2021.3632%2032.3068%2019.9718%2032.3068H18.4442C17.1997%2032.3068%2016.5774%2032.3068%2016.102%2032.0646C15.6839%2031.8515%2015.3439%2031.5116%2015.1309%2031.0934C14.8887%2030.6181%2014.8887%2029.9958%2014.8887%2028.7512V19.1957C14.8887%2017.9511%2014.8887%2017.3289%2015.1309%2016.8535C15.3439%2016.4354%2015.6839%2016.0954%2016.102%2015.8823C16.5774%2015.6401%2017.1997%2015.6401%2018.4442%2015.6401H18.8887C21.3778%2015.6401%2022.6224%2015.6401%2023.5731%2016.1246C24.4094%2016.5507%2025.0893%2017.2306%2025.5154%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512M25.9998%2035.6401V22.7512M25.9998%2035.6401L26.111%2035.4734C26.8828%2034.3156%2027.2687%2033.7368%2027.7786%2033.3177C28.2299%2032.9467%2028.75%2032.6684%2029.3091%2032.4986C29.9406%2032.3068%2030.6363%2032.3068%2032.0278%2032.3068H33.5553C34.7999%2032.3068%2035.4222%2032.3068%2035.8975%2032.0646C36.3157%2031.8515%2036.6556%2031.5116%2036.8687%2031.0934C37.1109%2030.6181%2037.1109%2029.9958%2037.1109%2028.7512V19.1957C37.1109%2017.9511%2037.1109%2017.3289%2036.8687%2016.8535C36.6556%2016.4354%2036.3157%2016.0954%2035.8975%2015.8823C35.4222%2015.6401%2034.7999%2015.6401%2033.5553%2015.6401H33.1109C30.6218%2015.6401%2029.3772%2015.6401%2028.4265%2016.1246C27.5902%2016.5507%2026.9103%2017.2306%2026.4842%2018.0668C25.9998%2019.0176%2025.9998%2020.2621%2025.9998%2022.7512'%20stroke='%23E7E7E7'%20stroke-width='1.125'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_1154_3945'%20x='0.5'%20y='0.140137'%20width='51'%20height='51'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeMorphology%20radius='1.5'%20operator='dilate'%20in='SourceAlpha'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeOffset/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%200.08%200%200%200%200%200.08%200%200%200%200%200.08%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_1154_3945'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_1154_3945'%20result='shape'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
Introduction
Today, we're thrilled to introduce ClipTagger-12B: a powerhouse 12B-parameter VLM that crushes Claude 4 Sonnet on video frame captioning while costing 17x less.
Developed through a collaboration between Inference.net and Grass, this open-source model represents a new class of specialized AI: workhorse models built for production workloads at internet scale.
The Problem: Video Understanding is Too Expensive
Every day, billions of video frames need to be processed for search, moderation, accessibility, and analytics. But the economics don't work. With frontier models charging $3-15 per thousand output tokens, even modest video processing becomes prohibitively expensive.
Consider a media company processing 100,000 video frames daily. Using GPT-4.1, this would cost over $186,000 annually. For a platform processing millions of frames, costs quickly reach millions of dollars. These economics have kept advanced video understanding limited to only the largest technology companies.
ClipTagger-12B: A Workhorse Model for Production
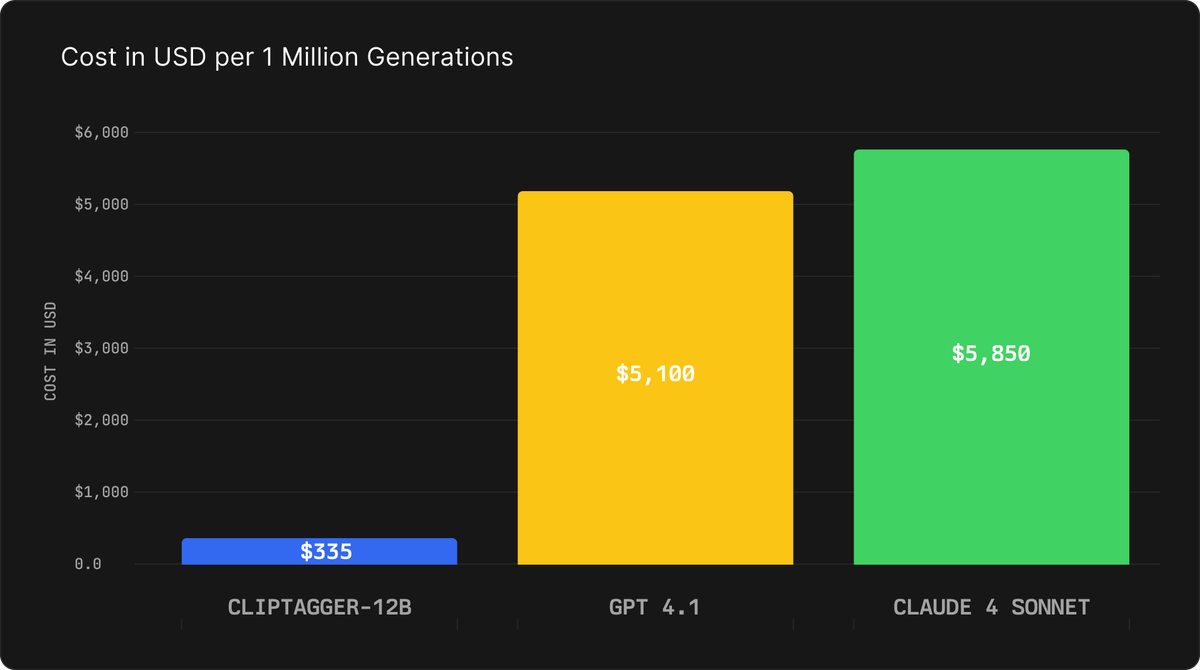
ClipTagger-12B solves this problem. At $0.30 per million input tokens and $0.50 per million output tokens, it delivers a 15x cost reduction compared to GPT-4.1 and 17x compared to Claude 4 Sonnet. For typical usage of 700 input tokens and 250 output tokens per frame, this equals $335 per million generations versus $5,100 for GPT-4.1 or $5,850 for Claude 4 Sonnet.
ClipTagger-12B isn't just another research model. It's a workhorse designed specifically for the demands of production video processing. The model generates structured JSON outputs for every video frame, making it ideal for:
Building searchable video databases at massive scale. The structured JSON output enables precise search capabilities. Natural language queries like "outdoor cooking tutorials with professional equipment" can match against specific fields in the JSON, returning results based on actual visual content rather than just metadata or titles.
Automating content moderation across platforms. The structured format allows moderation rules to be expressed as database queries. Platforms can flag content based on specific combinations of detected objects, actions, and environments, enabling more nuanced moderation policies that reduce false positives.
Creating accessibility tools with detailed scene descriptions. The comprehensive JSON output provides rich detail about objects, actions, and environments in each frame, making video content more accessible to visually impaired users through detailed audio descriptions.
Tracking brand visibility and ad verification. Advertisers can verify their ads appeared as contracted with concrete proof. Brands are detected in the logos field, products identified in objects, enabling automated tracking of screen time and context for each appearance.
Extracting insights from video libraries. Media companies can find all footage with certain objects, scenes, track production style trends, or identify reusable segments without expensive ML pipelines.
Performance That Matches Frontier Models
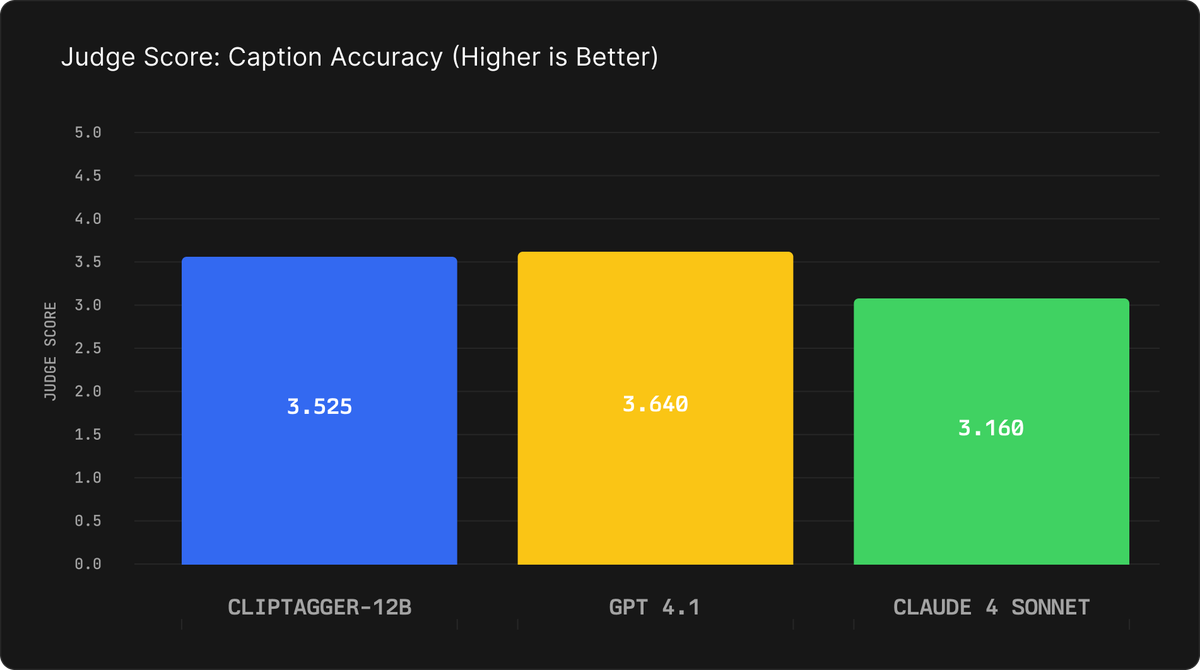
ClipTagger-12B achieves quality on par with GPT-4.1 while significantly outperforming Claude 4 Sonnet. Using Gemini-2.5-Pro as an independent judge to evaluate caption quality, the model scores 3.53 compared to 3.64 for GPT-4.1 and 3.16 for Claude 4 Sonnet.
When measured against the teacher model's outputs, ClipTagger-12B demonstrates strong alignment across all metrics:
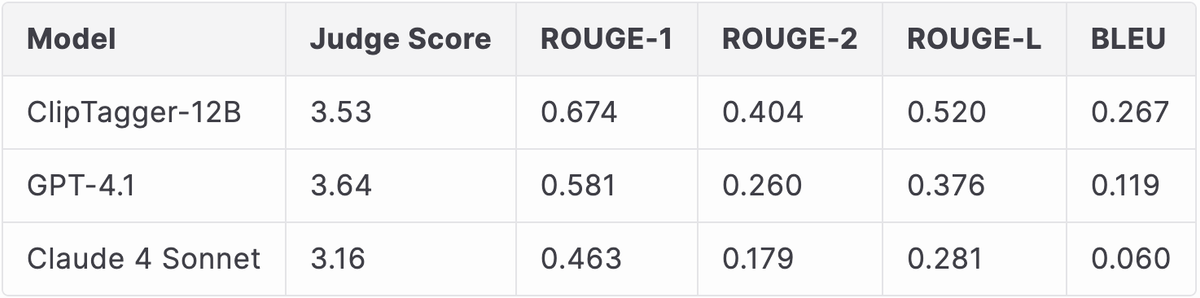
The ROUGE and BLEU scores measure alignment with the teacher model's annotations, showing that ClipTagger-12B successfully captured the teacher's capabilities through distillation. The model achieves 67.4% ROUGE-1, 40.4% ROUGE-2, 52.0% ROUGE-L, and 26.7% BLEU, indicating that our distillation process effectively transferred the teacher model's knowledge into the smaller, more efficient ClipTagger-12B.
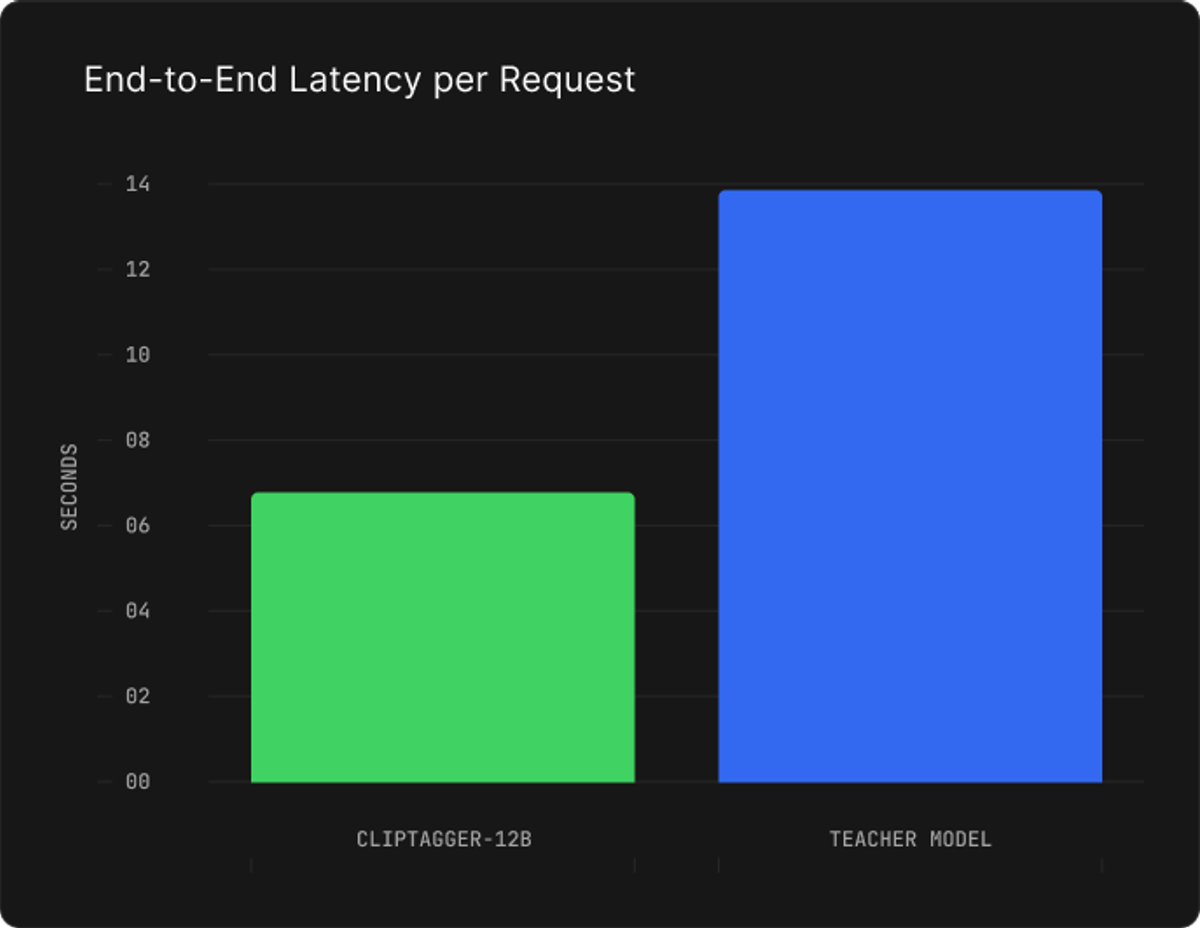
Beyond quality metrics, ClipTagger-12B delivers significantly faster inference. The model processes frames in approximately 6.5 seconds end-to-end, compared to 13.5 seconds for the teacher model, enabling high-throughput video processing applications:
Structured Output Built for Production Systems
ClipTagger-12B outputs structured JSON with a consistent schema for every frame. Given a nature scene with a wooden boardwalk through grassland it outputs:
{
"description": "A wooden boardwalk path extends from the foreground into the distance, cutting through a field of tall, vibrant green grass. The path is flanked on both sides by the dense grass. In the background, a line of trees is visible on the horizon under a blue sky with scattered white clouds.",
"objects": [
"Wooden boardwalk",
"Tall green grass",
"Blue sky",
"White clouds",
"Trees"
],
"actions": [],
"environment": "An outdoor, natural landscape, likely a marsh or wetland, on a clear day. The scene is characterized by a wooden boardwalk, lush green vegetation, and a bright blue sky with wispy clouds.",
"content_type": "real-world footage",
"specific_style": "landscape photography",
"production_quality": "professional photography",
"summary": "A wooden boardwalk path winds through a lush green field under a bright blue sky with scattered clouds.",
"logos": []
}This structure turns unstructured video into queryable data. Each field serves a specific purpose: objects enables product detection, actions captures what's happening, environment provides context, and production_quality helps filter content types. The schema was refined through months of iteration with Wynd to maximize utility while maintaining simplicity.
Technical Implementation
ClipTagger-12B is based on the Gemma-12B architecture, trained through knowledge distillation from a frontier vision-language model. We used one million carefully curated video frames from Grass's extensive video catalog for dataset creation.
The distillation process captured the teacher model's performance while reducing inference costs by 95%. We were able to achieve similar training results with both 12B and 27B variants of this distilled model, however the 12B model was an easy choice for its higher throughput and lower cost.
ClipTagger-12B is quantized to FP8 precision and shows no measurable quality loss vs BF16 based on judge scores. It’s specifically tuned for RTX 40-series and H100 GPUs, leveraging native FP8 support for high-throughput inference, and runs efficiently on a single 80 GB GPU.
Proven at Billion-Frame Scale
ClipTagger-12B has been tested and proven on billion-scale video libraries through our partnership with Wynd Labs. The model scales linearly with constant per-frame costs of $0.000335, whether processing thousands or billions of frames. This predictable pricing enables accurate budget planning even for the largest video libraries.
For high-throughput workloads, we support batch processing with webhook callbacks. Submit thousands of frames for asynchronous processing and receive results when complete. Enterprise customers can deploy on-premise or in their cloud with our containerized packages.
If you're planning to use ClipTagger-12B for large-scale workloads or search applications, contact us directly at partners@inference.net. We'll work with you to optimize deployment and ensure success at scale.
Custom Model Development
For organizations with unique requirements, we offer Custom LLM Training using the same distillation infrastructure that created ClipTagger-12B. Our process delivers:
- 50% faster generations with reduced latency
- Up to 95% cost reduction versus closed-source models
- Full model ownership with no vendor lock-in
- 30-day development from data to production deployment
Our team handles everything: data curation, model training, GPU procurement, benchmarking, and deployment or deployment support. Each model is optimized for the specific task, delivering frontier performance at a fraction of the cost.
Schedule a 15-minute consultation to discuss your use case. We'll quickly assess whether a custom model makes sense for your needs.
Availability
ClipTagger-12B is available today under Apache 2.0 license and is available for inference through our serverless API:
- API Access: Get $25 in free credits at inference.net/register
- Documentation: docs.inference.net/use-cases/video-understanding
- Model: Available on Hugging Face
The Shift to Task-Specific Models
ClipTagger-12B represents a broader trend in production AI. As frontier models grow larger and more expensive, the gap between their capabilities and practical deployment widens. Organizations need models that do specific tasks exceptionally well at sustainable costs.
This is where workhorse models excel. Rather than paying for general intelligence when you need specific capabilities, you deploy models optimized for your exact use case. The same distillation pipeline that created ClipTagger-12B can produce specialized models for medical imaging, industrial inspection, security monitoring, or any domain requiring visual understanding.
ClipTagger-12B was developed by Inference.net in collaboration with Grass. Special thanks to the Grass team for providing access to their video catalog and partnership throughout development. For custom model development, contact support@inference.net.
Meet with our research team
Schedule a call with our research team to learn more Specialized Language Models can cut costs and improve performance.