






Introduction
Not every LLM request needs an immediate response. Chat interfaces need real-time. But data extraction, enrichment, and background jobs can wait hours. This timing flexibility unlocks massive cost savings, though naive implementations create reliability nightmares.
This pattern is extremely common. A team needs to process hundreds of thousands of documents, so they write a loop that awaits each response. Then the script fails at request 1000 and they realize they need checkpointing, retries, rate limiting. Before long, they've built a distributed task queue just to call an API.
I recently found a 551-line Python file that started as a "simple" batch processor. It had custom rate limiting, exponential backoff, distributed locks, checkpoint files, and a state machine for resume logic. Here's the actual code. These kinds of one-off scripts are extremely common, and seem to spawn when you try to make synchronous APIs do batch work.
The tragedy here isn't the complexity. It's that after all that engineering, they were still not taking advantage of batch discounts!
This isn't to say that this strategy is wrong--for under 10k requests it might make perfect sense, as you get a quick response and may be able to sacrifice cost for quick turnaround. But at a certain scale this kind of script falls apart and becomes untenable to maintain.
That's why at Inference.net we built the most scalable batch LLM inference service available.
The Simple Test for Batch vs Real-Time
Here's how I decide: if the result goes into a database instead of a user interface, use batch. If someone's literally waiting for the response, use real-time.
This covers 90% of use cases. Data enrichment, classification, extraction, summarization, embedding generation, synthetic data creation - all batch. Chat interfaces, search suggestions, content recommendations - all real-time.
The middle ground is emerging too. Single requests that don't need immediate responses but don't fit neatly into batches. That's where asynchronous inference shines, but that's a topic for another blog post.
The Economics of Waiting
When you make a real-time API call, you're not paying for compute. You're paying for guaranteed availability.
Your provider promises an immediate response. To deliver that, they keep GPUs idling at well under full utilization, ready to serve your request instantly. You're literally paying for machines to wait around.
Batch processing breaks this model. Instead of demanding immediate responses, you give the provider up to 24 hours to complete your job. They pack your requests into idle GPU time, between the real-time requests, during off-peak hours. Same hardware, same models, but now you're only paying for actual compute.
This is why Inference.net can offer batch processing at 10% off (contact us for a larger discount for enterprise-scale workloads.) By using batch compute we can use our GPUs more effectively, and we pass these savings on to you.
Inference.net's Batch API
Instead of managing individual requests, with our Batch API you prepare your data upfront and hand it off. We handle all the complexity, including retries.
Here's the complete implementation that scales to millions of documents:
from openai import OpenAI
import json
client = OpenAI(base_url="https://api.inference.net/v1", api_key="inf-xxx")
# Prepare all requests upfront
with open("batch.jsonl", "w") as f:
for i, doc in enumerate(documents):
f.write(json.dumps({
"custom_id": f"doc-{i}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "meta-llama/llama-3.2-1b-instruct/fp-8",
"messages": [{"role": "user", "content": f"Classify: {doc['text']}"}],
}
}) + "\n")
# Submit and wait
file = client.files.create(file=open("batch.jsonl", "rb"), purpose="batch")
batch = client.batches.create(
input_file_id=file.id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
Now large workloads no longer require retry logic, rate limiting, or checkpoints. The platform handles everything internally, using battle-tested infrastructure designed specifically for this use case.
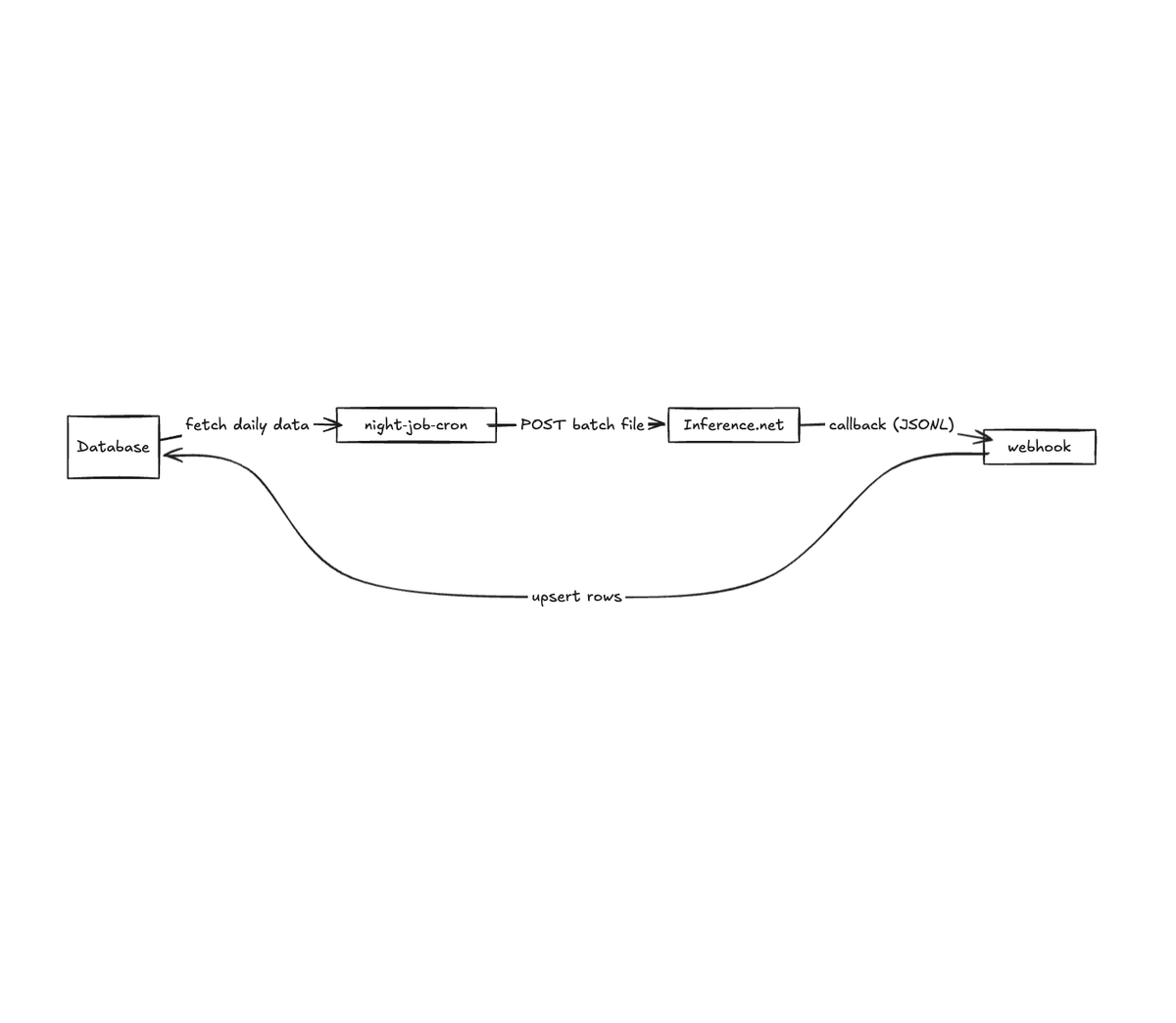
The Elegance of Webhook-Driven Batch Processing
Most of the best batch workflows I've seen use webhooks instead of polling. You submit your batch with a callback URL, then forget about it. When processing completes, you receive a POST request with results.
The goal of batch inference is typically to update a database. With the batch + webhook architecture, we can do this in a completely serverless if we want!
When Even Batch Isn't Enough
At true internet scale, even batch pricing adds up. When you're processing tens of millions to billions of requests monthly, it's time to consider advanced optimizations.
Model distillation is the most powerful approach. At Inference.net, we provide end-to-end task-specific model training where we use a large model to generate high-quality labels for your specific task, then train a smaller model that runs at a fraction of the cost. This works especially well with batch processing since distilled models often have similar request patterns.
Because Inference.net already offers rock-bottom prices by renting unused compute, our batch rates are hard to beat. But for truly massive workloads with repetitive structures, we also offer dedicated instances with KV cache optimization. When millions of requests share common prefixes (like classification prompts or extraction instructions), pre-populating the KV cache can reduce costs even further. The combination of model distillation, batch processing, and prefix caching can achieve up to 95%+ cost reduction compared to synchronous APIs.
If you are spending over 10k/mo on LLM inference, contact us! These optimizations could transform your economics.
Making the Switch
If you're still running batch workloads through synchronous APIs, switching is straightforward. Export your data to JSONL format where each line is a complete request. Upload the file, start the batch, retrieve results when complete.
At Inference.net, our infrastructure is uniquely suitable to batch workloads. While others treat batch as an afterthought, we aggregate idle GPU capacity across data centers to allow for cheap serverless inference, but even cheaper batch processing. We can offer 10% discounts on already low prices, with larger discounts for serious volume.
But what about those requests that fall between real-time and batch? The ones that don't need instant responses but also don't fit neatly into bulk processing?
That's where our Asynchronous API and Group API come in. The Asynchronous API lets you fire off individual requests and get results when ready, while the Group API handles up to 50 related requests as a unit - perfect for processing a user's uploaded documents or analyzing a thread of messages together.
For some workflows the asynchronous API can have serious advantages over large batches while providing the same discounts. Our next article, The Cheapest LLM Call Is the One You Don't Await, explores how async requests can improve developer experience for background tasks.
Own your model. Scale with confidence.
Schedule a call with our research team to learn more about custom training. We'll propose a plan that beats your current SLA and unit cost.