
RAG has hit its ceiling and RL-trained agents just blew past it.
For a while, we could consistently improve retrieval with just better embeddings and re-rankers. The state of the art was relatively simple: you'd typically end up doing a sparse search (BM25/SPLADE), a dense embedding search, and then rerank either with RRF (Reciprocal Rank Fusion) or a cross-encoder. This was more than enough to take your search quality pretty far.
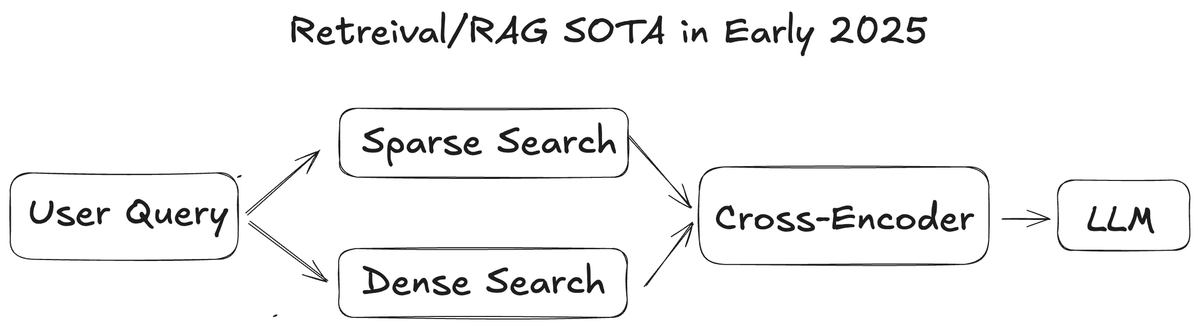
Of course we could do much better with a more sophisticated pipeline, especially if you have user preference data. But the above alone could give very significant gains.
Then something interesting happened: engineers found that when you give an LLM tools, run it in a loop (the definition of an agent), and ask it to perform retrieval, it regularly outperforms a carefully tuned single-step search pipeline even when the search tools the agent is given are mediocre. This agentic approach showed promise—but it was expensive and slow.
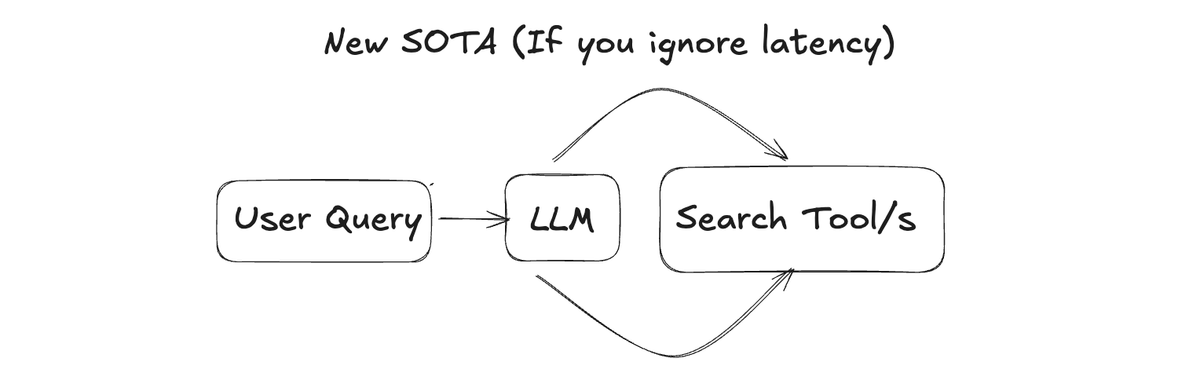
On the surface, this was nothing new — the idea of LLMs performing multiple searches in a row was already somewhat explored and referred to as multi-hop retrieval (see Baleen). While promising, it was an expensive and slow optimization that improved search quality but wasn't necessarily transformative.
Upon looking closer, something was brewing in the search space. Agents can now use multiple tools, including grep, embedding search, and explore structured data in sophisticated ways. LLMs are now strong enough to cleverly solve the hurdles that occur in complex search tasks, and have reached a level of proficiency with multiple tools that has unlocked a fundamentally new search capability. Part of this is due to RL now being a standard step in training foundation models, and models are rewarded for being very good at using a wide array of tools.
Still, every search system is different. Searching a codebase is fundamentally different from searching research papers, and that's different from searching people/companies. While an agent could masterfully use tools, it didn't have the experience of a person who has been using a particular search engine for a very long time and knows how to use it effectively.
Using agents to search is also expensive — the context would quickly balloon, and large, costly LLMs would usually significantly outperform smaller ones, but at a significant latency and monetary cost.
RL takes search agents to the next level. Without RL, agentic search is powerful but slow; you often need expensive frontier models to get the best results. With RL, it becomes much more viable.
Recent research confirms this pattern: RL drastically improves search systems. DeepRetrieval, with just 3B parameters, reports outperforming GPT-4o and Claude-3.5-Sonnet on 11/13 datasets, including benchmarks such as HotpotQA, for query augmentation and evidence-seeking retrieval. While gains over the base retriever were marginal on some benchmarks, this likely reflects data contamination—the base retriever (BGE-base-en-v1.5) was explicitly trained on those same benchmarks, artificially inflating its performance.

Search-R1 shows that reinforcement learning can meaningfully boost agentic retrieval. With RL, Qwen-2.5 3B and 7B learn to issue multi-turn web search queries, reason over results, and decide when to search again. Across seven QA datasets, the paper reports relative gains of about 21% for 3B and 26% for 7B over strong RAG baselines. Unlike vanilla RAG, the model is trained to actively investigate: it searches when needed, stops when it has enough evidence, and can alternate between reasoning and searching.
This same principle applies beyond just web search. You can train a small LLM to operate an entire toolbelt—keyword search, semantic search, grep, SQL—and through RL, it learns to use them judiciously. The reward function shapes the behavior: punishing hallucinations, rewarding correct retrievals, penalizing excessive tool calls. What emerges is a model that's superhuman not just at finding information, but at knowing which tool to use when, and synthesizing what it finds into coherent answers.
Even though LLMs can be RL'd to excel at both retrieval and generation, we may see specialized small models handle retrieval while frontier models focus on generation. This division makes sense: retrieval is where RL shines most, and it's the bottleneck—slow, expensive, and domain-specific. Frontier models excel at the final generation step (coding, long-form writing), but they struggle with efficient, domain-aware retrieval. This inefficiency is what's destroying margins and increasing latency for startups building agentic search systems.
Your latest experience with this evolution may have been Grok Code (xAI's coding agent), which shows what happens when you apply RL to agentic search. While other frontier LLMs are were slow and expensive for coding, Grok Code is “ridiculously fast.” Based on xAI’s update on grok-code-fast-1, xAI carefully reinforced to retrieve only the relevant context from your codebase and execute correct actions without wasting cycles.
A big reason Grok Code is so good at agentic coding is that it's a single model trained to handle the entire workflow: finding relevant code, executing commands, making edits, reacting to errors, all in one integrated loop. When you're actively coding in Cursor, you need this unified agent because each action informs the next. A failed test might require checking logs, which reveal a different file needs editing, which triggers another search. A single RL-trained model excels here because it is able to adapt to this entire universe of possible necessary actions.
But many workflows don't need this real-time adaptability. Most RAG systems work in two distinct stages: first, gather all relevant context (for a code review bot, this might be what files changed, what they connect to, and relevant documentation); second, synthesize that information into a judgment or summary. These stages have different requirements. Retrieval needs to be fast and comprehensive, while synthesis needs to be thoughtful and accurate. Training a small specialized model for the retrieval stage, then handing off to a frontier model for synthesis, often works better than forcing one model to do both. It's the same principle as when we used to fine-tune embeddings or re-rankers: specialize where it counts.
Startups are already building agentic search, but there are obvious signs that RL can bring easy wins. Happenstance—a search engine for your contacts—is a good example. The search agent feels magical, creating complex filters on the fly. But as of this writing, the search is too slow—a classic symptom of agentic search without RL optimization. This is exactly where RL would transform it from “magical but impractical” to “magical and usable,” likely achieving the 2–3×+ speedups we've seen in our other fine-tunes.
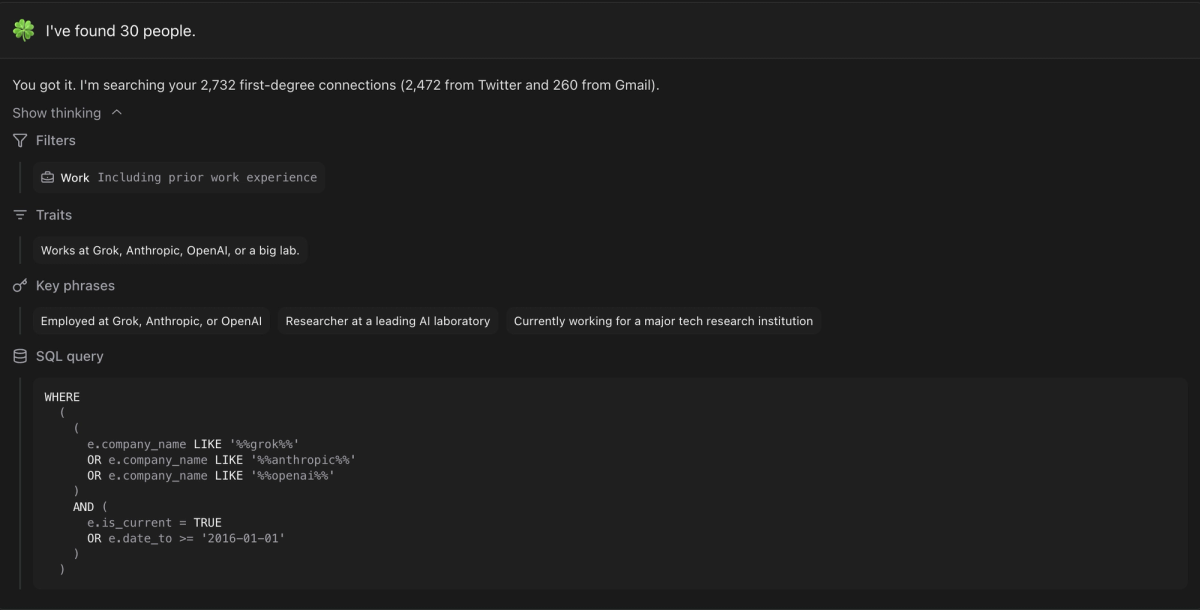
Clado, another YC startup, used LLM-as-Judge RL loops to improve their people search product.
RL-powered agentic search is becoming the meta. Pure agentic search showed us what was possible; RL makes it practical. It may feel different from the previous meta of training embedding models and choosing the right reranker, and it's definitely less straightforward, but the massive gains make it worth it. The fundamentals haven't changed: you still need evals and training data, though you may need less data since it's now used for a reward function rather than direct supervision.
The progression is becoming crystalized: traditional RAG hit a ceiling, agentic search broke through it but at prohibitive cost, and now RL makes agentic search both superior AND efficient.
While the combination of RL and agentic search is powerful, you still need to wrangle data, find the right examples, and deploy effectively. It's specialized ML work that takes real expertise.
That's what we do at inference.net. We train custom models for your exact use case, whether it's RL-powered agentic search, data extraction, or real-time chat. Our team handles everything: building evals, designing reward functions, integrating tools, training models, and deploying at scale. Most founders are trying to find product-market fit, not become ML experts. We handle the model infrastructure while you build your business.
Paper links referenced above (for convenience): • SPLADE • RRF • Baleen • DeepRetrieval • Search-R1 • HotpotQA • BGE-base-en-v1.5